
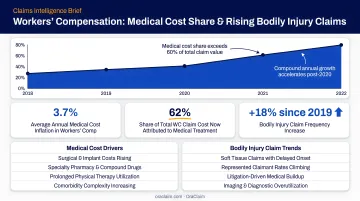
The scale of the problem is real. According to LexisNexis Risk Solutions, bodily injury paid amounts grew from less than 20% of total claims dollars in 2022 to more than 26% in 2025, while BI claims per 100 property-damage claims rose from 24 to 29. More injury claims means more medical records, more reconciliation work, and more room for error.
This article covers why EHR and claims data integration matters specifically for defense teams, the core challenges that make integration hard, and the best practices that separate high-performing platforms from generic middleware.
Key Takeaways
- Siloed EHR and claims data forces manual reconciliation that slows review cycles and introduces strategic errors
- The hardest integration problems involve unstructured clinical text, format mismatches across EHR vendors, and HIPAA compliance across the full technology stack
- Audit data sources and adopt FHIR R4 and EDI X12 before platform selection — data quality validation must happen before records reach analysts or attorneys
- Integrated AI platforms can surface inconsistencies, generate medical chronologies, and benchmark cases automatically, making document review a strategic function rather than a cost center
Why EHR and Claims Data Integration Matters for Defense Teams
Defense teams work with two fundamentally different data types that almost never arrive in the same place.
EHR data is clinical: treatment notes, imaging reports, discharge summaries, prescription histories, and diagnostic codes generated by healthcare providers. Most of it is unstructured. Claims data is administrative: coverage details, reserve amounts, billing codes, prior claim histories, and financial records generated by insurance systems. Most of it is structured but fragmented across carriers, TPAs, and practice management platforms.
Neither source tells the complete story on its own. A reserve decision made without access to the full treatment timeline is a guess. Without cross-referencing prior claim history, an injury causation argument is exposed.
The Operational Cost of Siloed Records
When EHR data sits separate from claims history, someone must manually cross-reference them. That manual work typically involves:
- Identifying pre-existing conditions by reading through clinical notes
- Spotting treatment gaps by comparing appointment dates against claimed injury timelines
- Finding inconsistencies between diagnoses and claimed injuries line by line
This work is time-intensive, error-prone, and largely non-billable — and it compounds across every file in the queue, not just complex ones. That operational drag sets the stage for a deeper problem at the portfolio level.
The Strategic Cost of Fragmented Data
The real competitive disadvantage shows up at the portfolio level. When past EHR data is not linked to claim outcomes — settlement amounts, litigation duration, reserve accuracy — defense teams cannot identify patterns across similar cases. Every evaluation starts from scratch.
NCCI's 2025 State of the Line Guide reported that medical costs made up approximately 90% of total costs for workers' compensation claims with $5M or more in total incurred losses. High-severity files are, almost entirely, medical record problems. Teams that cannot efficiently process that medical data are at a structural disadvantage precisely where the financial exposure is highest.
The Biggest Challenges When Integrating EHR and Claims Data
Unstructured Medical Record Data
This is the hardest single step. A 2023 peer-reviewed study found that unstructured data — free-text clinical notes, discharge summaries, scanned documents — comprises over 80% of digital healthcare information.
Unlike claims data, which uses standardized codes (ICD-10, CPT, EDI X12), most EHR content has no consistent schema. Before it can be mapped to claim fields, it must be parsed, extracted, and normalized. Without natural language processing capable of handling clinical text, this step simply doesn't scale.
Format and Coding Inconsistencies Across Systems
EHR vendor fragmentation makes the parsing problem worse. According to KLAS data reported by Fierce Healthcare, acute-care EHR market share in 2024 broke down as:
- Epic: 42.3%
- Oracle Health: 22.9%
- Meditech: 14.8%
- TruBridge: 7.6%
Each vendor produces records in different formats — HL7 v2, FHIR, CCD/CDA — while claims systems use EDI X12 transactions or proprietary schemas. Without a transformation layer that reconciles these formats, integration breaks at the handoff between clinical and claims environments.
Data Completeness and Accuracy Gaps
Claims data frequently contains missing fields, duplicate records, or stale coverage information. EHR data can have incomplete treatment histories when a claimant sought care across multiple providers.
Data quality validation must happen before records are merged, not after. In a litigation context, a duplicate claimant record that slips through can corrupt a medical chronology. A missing prior claim can undermine a causation defense built on incomplete history.
HIPAA Compliance During Data Exchange
Integrating EHR data into a claims or legal platform triggers compliance obligations at every layer. That includes the integration platform itself and every downstream system consuming the data — AI tools, analytics engines, and reporting dashboards included. At minimum, you need:
- Executed business associate agreements (BAAs) with all vendors handling PHI
- Minimum necessary access controls limiting data exposure to what each use case actually requires
- Detailed audit logging covering every access, transfer, and transformation event
The stakes are concrete. OCR reported 732 large breach notifications in 2023 affecting approximately 113 million individuals. Raleigh Orthopaedic Clinic paid a $750,000 penalty after sharing PHI with a vendor without a BAA in place.
Legacy System Friction
HIPAA compliance adds overhead, but legacy infrastructure adds friction of a different kind. Many carriers and defense firms still operate claims administration systems that predate modern API standards. Bidirectional data exchange with these systems requires custom connectors or middleware, and a single lift-and-shift migration rarely works.
Phased approaches work better: connect the highest-priority data sources first, stabilize those integrations, then expand. This sequence reduces disruption while delivering usable data faster.
Best Practices for EHR and Claims Data Integration Platforms
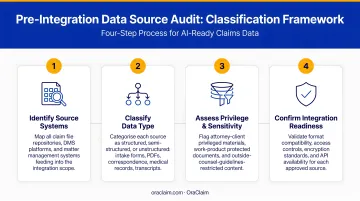
Audit and Classify Your Data Sources Before Integration
Before selecting or configuring any integration platform, map every data source that will feed the pipeline. For each source, document:
- Format type (FHIR, HL7 v2, EDI X12, PDF, proprietary)
- Update frequency (real-time, batch, on-request)
- Data quality level (completeness, known gaps, duplicate rates)
- Strategic priority for case review
This pre-integration audit prevents downstream mismatches and helps teams allocate integration resources toward the connections that actually move case strategy — rather than connections that simply exist.
Adopt Healthcare Interoperability Standards from the Start
Platforms built on FHIR R4 and HL7 v2 provide the most durable foundation for EHR data exchange. CMS-0057-F requires impacted payers to implement FHIR-based APIs, including a Provider Access API by January 1, 2027. ONC's HTI-1 rule adopts HL7 FHIR Release 4.0.1 as a foundational base standard in certification requirements.
For claims transactions, EDI X12 — specifically the 837 Health Care Claim transaction — remains the standard backbone.
Insist on out-of-the-box support for these standards rather than accepting custom parsers for every connection. Custom-built parsers create technical debt and fail every time a source system updates its format, requiring expensive engineering intervention to restore the connection.
Build API-First, Real-Time Data Pipelines Where Possible
Batch file transfers via FTP or flat files were acceptable when claim volumes were manageable. At today's claim volumes, they create dangerous lag. API-driven, real-time data exchange gives defense teams access to updated medical records as they arrive, which can change case strategy, reserve decisions, and settlement authority before a scheduled review cycle catches up.
API-first architectures also make it easier to add new data sources without re-engineering the pipeline from the ground up. New connections — additional EHR vendors, court filing systems, third-party medical review services — plug in rather than requiring full rebuilds.
Establish Clear Data Transformation and Mapping Rules
Every integration project requires a transformation layer that translates source formats into a unified internal schema. In the claims defense context, that means mapping:
- ICD-10 diagnosis codes → injury type and causation category
- CPT procedure codes → treatment category and cost benchmarks
- Claims billing records → reserve buckets and LAE categories
Document, version-control, and have both technical teams and legal or claims SMEs review every mapping rule. Clinical meaning is easily lost in translation. A miscoded injury type can corrupt every downstream case evaluation that relies on it.
Implement Data Quality Validation Gates
Insert automated validation checks at each stage of the pipeline — before ingestion, during transformation, and before data reaches end users. Validation gates should flag:
- Duplicate claimant records
- Missing required fields (date of loss, claimant ID, provider NPI)
- Out-of-range values (claim amounts, treatment dates that precede the incident)
- Identity mismatches between claimant demographics in EHR versus claims systems
CAQH data shows that manual medical claim submission costs $6.74 per transaction versus $3.20 electronically. Validation errors that force manual remediation eliminate much of that efficiency gain. In litigation, they create something worse: strategic decisions built on bad data.
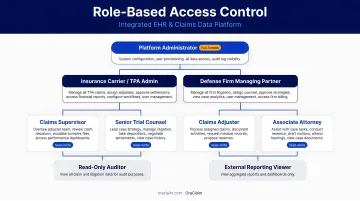
Design for Scalability and Role-Based Access
A well-designed integration platform should handle growing claim volumes without requiring re-architecture. On the access side, integrated EHR and claims data must be governed by role.
Attorneys may need full record access. Paralegals may need medical chronology outputs without underlying claim financials. Claims adjusters may need reserve data without attorney work product. Role-based access controls satisfy both operational security requirements and HIPAA compliance obligations for any platform handling protected health information.
Security, Compliance, and Data Governance
The Non-Negotiable Security Baseline
Any platform handling integrated EHR and claims data must meet these minimum controls:
- End-to-end encryption for data in transit and at rest
- Multi-factor authentication for all users
- Detailed audit logging of who accessed which records and when
- Clear data retention and deletion policies
These controls must apply not just to the integration layer but to every downstream system that consumes the integrated data — analytics tools, AI platforms, reporting dashboards.
Governance: Who Owns What
Data governance in this context means answering specific questions before integration goes live:
- Which system is the authoritative source of record for each data field?
- How are conflicts between EHR and claims data resolved?
- Who is authorized to modify transformation rules?
- Who owns each data field when records are merged?
Without a shared governance model, different teams interpret integrated data differently. Reserve decisions diverge, case evaluations conflict, and the integration ends up generating disputes rather than resolving them.
BAA Coverage Across the Full Stack
HIPAA requires business associate agreements whenever EHR data is shared with legal platforms or third-party vendors. This obligation extends to the entire integration stack — including any AI or analytics layer sitting on top of the integrated data.
OraClaim addresses this by operating as a closed, access-restricted system where all third-party infrastructure operates solely as sub-processors contractually prohibited from accessing or using confidential information beyond transient processing. Sub-processors cannot use client data for model training, independent analysis, or human review without explicit customer authorization.
Defense firms evaluating any integration platform should confirm BAA coverage extends to every component — not just the primary interface.
How AI Unlocks the Full Value of Integrated EHR and Claims Data
Raw integration — connecting EHR and claims systems — is necessary but not sufficient. Integrated data only becomes strategically valuable when an AI layer can analyze it at scale.
From Records to Structured Intelligence
Given that over 80% of clinical data is unstructured, AI's first job is extraction. Natural language processing parses free-text clinical notes, identifies diagnosis language, extracts treatment timelines, and flags causation statements — converting hundreds of pages of records into structured outputs that attorneys and adjusters can act on without reading every page.
OraClaim's medical chronology module illustrates what this looks like in practice. The system ingests raw medical records across all source types:
- ER reports, hospital records, and specialist notes
- Imaging reports, pharmacy records, and IME reports
- Treating physician depositions
From those inputs, it produces structured chronologies with date, provider, diagnosis, treatment, medication, complaint, and outcome columns. It extracts ICD-10 and CPT codes, flags treatment gaps, surfaces pre-existing conditions, and annotates inconsistencies between subjective complaints and objective findings. Output is available in Word, PDF, Excel, or CSV — with optional pin-citations to underlying record pages.
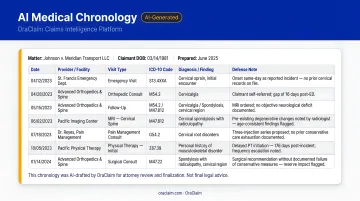
The drafting time drops from 15–60+ hours per file to under 60 minutes for a first draft.
Case Benchmarking at Scale
When historical EHR data is linked to claim outcomes, AI can identify patterns that human review never surfaces at volume. OraClaim's benchmarking module auto-tags each claim across dozens of dimensions — case type, jurisdiction, venue, judge, plaintiff counsel, plaintiff expert, alleged injuries, treatment patterns, reserve range, and motion practice outcomes — then benchmarks every new claim against the historical book.
Defense teams receive comparables showing prior settlement and verdict ranges for similar fact patterns, plaintiff-counsel-specific outcome histories, and judge-specific motion-grant rates. Every closed case becomes structured intelligence for the next one. Benchmarking models are built from each client's own historical data, with complete segregation between organizations.
Surfacing the Discrepancies That Change Cases
AI-powered claim file review also flags what manual review misses under time pressure: inconsistencies between claimed injuries and documented treatment, gaps in the timeline that undercut causation arguments, non-compliance patterns, and prior accidents that the claimant didn't disclose.
These findings directly shape reserve decisions and settlement authority. A treatment gap identified at intake costs far less to address than the same gap discovered during deposition prep — which is why early AI-assisted review has become a core part of how defense teams control exposure before it compounds.
Frequently Asked Questions
What is the difference between EHR data and claims data in a defense context?
EHR data is clinical — diagnoses, treatment notes, prescription histories, imaging results. Claims data is administrative and financial — coverage details, billing codes, reserve amounts, prior claim history. Integrating both creates a complete picture that neither source provides alone.
Why is integrating EHR and claims data so difficult?
EHR data is largely unstructured and uses clinical standards (FHIR, HL7, ICD-10), while claims data uses financial and administrative schemas (EDI X12, proprietary formats). Reconciling the two requires a dedicated transformation layer that handles free-text extraction, format mapping, and data quality validation at the same time.
What security standards should an EHR and claims data integration platform meet?
The minimum baseline includes HIPAA compliance with BAAs covering the full technology stack, end-to-end encryption for data in transit and at rest, multi-factor authentication, role-based access controls, and detailed audit logging. Every downstream system that consumes integrated data — including AI tools — must be covered under appropriate BAAs.
How does data integration improve outcomes for defense teams?
Integrated data lets defense professionals spot inconsistencies between claimed injuries and documented treatment, benchmark against historical outcomes, and set more accurate reserves. The result is faster case decisions with less exposure to strategic errors from incomplete records.
Can AI tools work with integrated EHR and claims data to support litigation strategy?
Yes. AI platforms built for defense work can parse integrated data to extract key facts, generate medical chronologies, identify patterns across similar cases, and flag discrepancies automatically. What would otherwise take hundreds of hours of manual review becomes near-instant, litigation-ready analysis.
What should defense firms look for when evaluating an EHR and claims data integration platform?
Look for support for healthcare interoperability standards (FHIR R4, HL7 v2, EDI X12), built-in HIPAA compliance with BAA coverage across the full stack, API-first architecture for real-time data exchange, role-based access controls, and scalability for high claim volumes. Prioritize platforms with an AI layer purpose-built for defense and claims — not general healthcare IT middleware adapted for legal work.


