Manual review was never designed to handle the volume or complexity of modern fraud schemes. Adjusters working through individual files cannot see the cross-claim patterns that reveal coordinated attorney-claimant-provider networks. Rule-based systems generate false alarms at scale. And according to a 2024 Gen Re survey, only 33% of claims organizations use system automation to identify suspicious indicators — meaning the majority still rely primarily on manual detection.
This article explains how AI-driven fraud detection works within claims management software, which technologies power it, why it matters for defense-side claims professionals specifically, and what to look for when evaluating a platform.
Key Takeaways
- Insurance fraud costs the U.S. $308.6B annually; only 33% of organizations use automated fraud detection
- AI flags anomalies in real time across structured claim data and unstructured documents like medical records
- Supervised and unsupervised machine learning catch both known fraud patterns and emerging schemes
- Graph-based network analysis surfaces coordinated fraud rings invisible to per-claim review
- AI benchmarking gives defense teams visibility into attorney demand patterns, provider billing outliers, and portfolio anomalies
- Purpose-built platforms outperform generic financial services tools for claims-specific document processing
The Fraud Problem in Claims Management: Why Manual Review Falls Short
The Volume Problem
The 2024 Workers' Comp Benchmarking Study found 21% of indemnity adjusters carry 126–150 claims simultaneously, with 29% of medical-only adjusters managing more than 200. An adjuster at that caseload cannot cross-reference whether the same chiropractor, plaintiff attorney, or claimant appears across 40 other files in the portfolio. Pattern detection at that volume requires technology — full stop.
The consequence is that fraud operating at the network level goes undetected for months, sometimes years. By the time a pattern is flagged through manual review, costs have already compounded across dozens of claims.
Why Rule-Based Systems Don't Solve It
Most organizations that do use automation rely on rule-based systems — fixed thresholds that trigger alerts when a claim exceeds a dollar amount, a treatment duration, or another predefined variable. The problems are well-documented:
- High false-positive rates that waste SIU capacity and delay legitimate claim payments
- Inability to process unstructured documents like medical narratives, demand packages, or physician notes
- Rigid triggers that miss fraud operating just below the threshold
- No cross-claim visibility — rules run at the individual claim level, not across the portfolio
High false positives create a compounding problem: investigation resources chase phantom alerts while actual fraud accumulates undetected across the portfolio.
The Sophistication Gap Is Widening
Fraud schemes have adapted to exploit exactly these gaps. Verisk's 2026 insurance fraud study found 99% of insurers have encountered manipulated or AI-altered documentation, and 76% report that AI-altered submissions became more sophisticated in the prior year. Exaggerated injuries, coordinated provider billing, and organized attorney-claimant networks have adapted faster than the detection systems built to catch them.

How AI-Driven Fraud Detection Works in Claims Management Software
The Foundation: Structured and Unstructured Data Together
Traditional systems process structured data — claim numbers, billing codes, dates, dollar amounts. AI systems go further by ingesting unstructured data simultaneously: medical narratives, legal demand letters, physician notes, deposition transcripts. By combining both data types, AI establishes baselines for normal claim behavior across thousands of variables and flags deviations as they emerge.
This real-time analysis is what separates AI from rule-based approaches. Rather than waiting for a threshold to be crossed, AI continuously monitors each claim's trajectory against historical patterns and surfaces anomalies as they develop.
Supervised Learning: Recognizing Known Fraud Patterns
Supervised machine learning models are trained on large datasets of confirmed fraudulent and legitimate claims. The model learns to associate specific feature combinations with fraud probability — including:
Supervised machine learning models are trained on large datasets of confirmed fraudulent and legitimate claims. The model learns to associate specific feature combinations with fraud probability — including:
- Billing for procedures not performed
- Injury severity inconsistent with the reported incident mechanism
- Treatment timelines that predate the recorded loss date
These models perform well on known fraud typologies. When a new claim exhibits the same pattern of features as confirmed fraud in the training data, the model flags it with a high confidence score and supporting rationale.
Unsupervised Learning: Catching What Nobody Has Seen Before
Supervised models have a ceiling: they can only recognize fraud patterns already present in training data. Unsupervised anomaly detection works differently. It identifies statistical outliers and unusual claim trajectories without needing labeled examples.
This matters because fraud schemes evolve. A new billing code manipulation or an emerging staged-accident network won't appear in historical training data. Unsupervised models surface these behaviors by recognizing that something is statistically unusual, even when they can't categorize exactly why. One 2025 hybrid unsupervised model applied to a real-world insurance dataset reported 92% accuracy and 96% recall. Those results came from a single dataset, so they shouldn't be extrapolated across all lines of coverage — but they illustrate the detection ceiling this approach can reach.

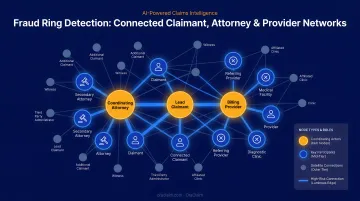
Network and Pattern Analysis: Surfacing Fraud Rings
Graph-based AI maps relationships between claimants, attorneys, medical providers, and employers across an entire claims portfolio. When the same provider appears in 60 claims, all of which involve the same two plaintiff attorneys, and the treatment patterns are statistically identical — that's a fraud ring. Reviewed claim by claim, those connections are invisible.
Verisk's network analysis capability, powered by more than 1.9 billion claims records, illustrates how industry-scale relationship mapping compresses what would otherwise be weeks of multi-claim investigation into hours. The principle applies at any portfolio scale: cross-claim relationship data changes what's visible.
SIU Referral Workflow
Once AI flags a suspicious claim, it generates a data-driven justification — specific anomalies, relationship maps, supporting document evidence — that gives adjusters and claims managers the confidence to escalate without fear of unfounded accusations or regulatory exposure. That documented rationale is critical: SIU referrals without defensible justification create compliance risk and wasted investigative resources.
Key AI Technologies Behind Claims Fraud Detection
Natural Language Processing (NLP)
NLP enables AI to extract meaning from unstructured documents that rule-based systems can't touch. Applied to medical records and demand packages, NLP identifies:
- Treatment dates that predate the incident
- Diagnoses inconsistent with the mechanism of injury
- Subjective complaints that contradict objective clinical findings
- Language patterns common to exaggerated or templated claims
OraClaim's AI document review, for example, automatically extracts dates, injuries, and clinical events from medical records, then flags timeline gaps, causation inconsistencies, and treatment concerns — surface-level reading that would otherwise consume hours of attorney or adjuster time.
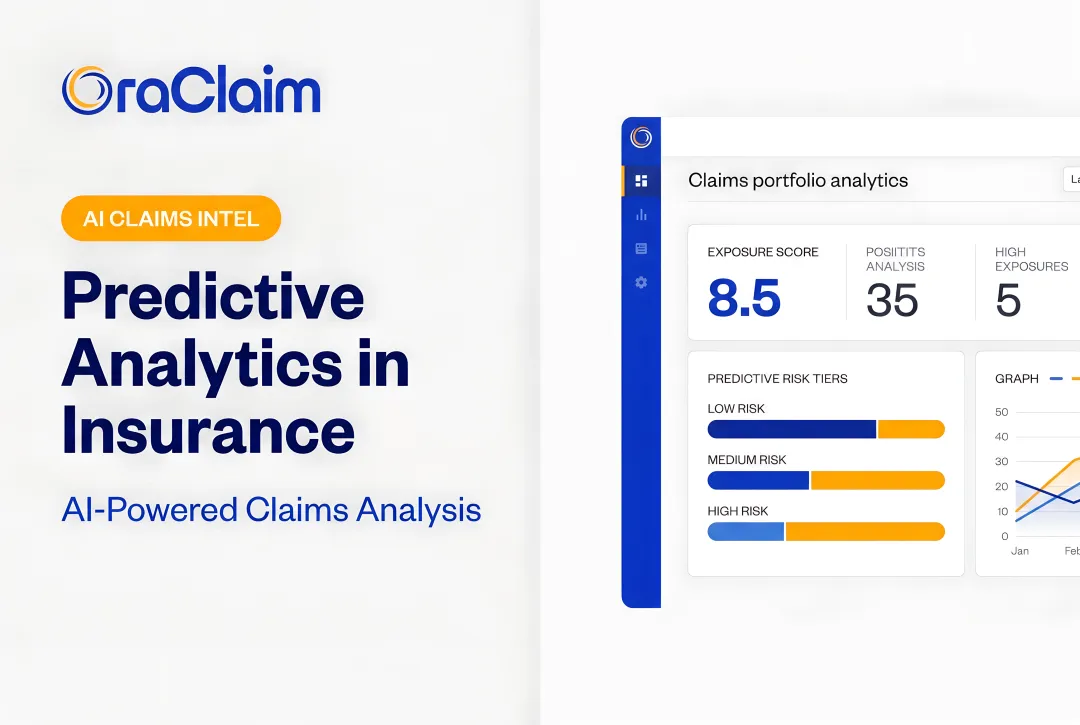
Predictive Analytics and Risk Scoring
AI uses historical claims data to generate risk scores for incoming claims based on claim type, geography, involved parties, and early trajectory. This enables proactive triage: high-risk claims receive attention earlier, before costs escalate, rather than waiting for the reactive investigation that typically follows manual detection.
OraClaim's real-time exposure analysis continuously re-scores each claim as new documents arrive, flagging material changes to reserve adequacy, liability assessment, and settlement value. Claims exhibiting patterns associated with inflation or exaggeration surface automatically.
Machine Learning Pattern Recognition
ML models continuously refine themselves as they process more claims data. Unlike rule-based systems that require manual updates when fraud tactics shift, ML models adapt and improve accuracy over time without administrator intervention.
Key capabilities that separate ML from static rules-based detection:
- Identifies emerging fraud patterns before they're codified into manual rules
- Reduces false positives as the model learns legitimate claim trajectories
- Prioritizes anomalies by severity, not just by rule-match frequency
Computer Vision and Document Forensics
AI can analyze uploaded images and scanned documents for signs of alteration, duplication, or fabrication. Verisk's Digital Media Forensics capability, for instance, identifies tampered loss photos, detects preexisting damage misrepresented as incident-related, and flags timestamps inconsistent with the reported loss date. This layer of detection addresses the growing problem of AI-altered documentation — a problem 99% of insurers now report encountering.
Generative AI for Claims Summarization
Lengthy claim files — sometimes hundreds of pages of medical records, reports, and correspondence — create a practical problem: the fraud-relevant facts are buried in volume. Generative AI synthesizes these files into concise, actionable summaries that surface key inconsistencies without requiring reviewers to read every document.
OraClaim's claim file review module reduces total review time by half or more, generating structured key fact summaries, anomaly flags, and citation-linked indexes that make critical details immediately accessible.
Beyond Insurers: How AI Fraud Detection Serves Defense Claims Professionals
Most fraud detection tools are marketed to carriers and insurers. Defense lawyers and claims managers face a parallel challenge that receives less attention: identifying which claims are inflated or exaggerated so they can build stronger defenses, challenge medical evidence, and prioritize litigation strategy on genuine exposures.
The Defense-Side Intelligence Gap
Defense organizations managing hundreds of active claims simultaneously cannot manually cross-reference plaintiff attorneys, medical providers, or claimants across their entire portfolio. Without systematic cross-claim analysis, these patterns stay invisible.
The plaintiff attorney who routinely inflates demands. The chiropractor appearing across dozens of files with identical billing. The claimant with prior accidents. AI surfaces these connections continuously — changing how a defense team values and prioritizes each file.
How Pattern Recognition Supports Defense Strategy
When AI benchmarks an incoming claim against thousands of similar historical cases, it surfaces data points that directly inform defense posture:
- Plaintiff attorney history: settlement ranges, litigation behavior, and outcomes across comparable fact patterns
- Provider billing outliers: billing that deviates significantly from peer providers across similar cases
- Expert witness reliability: prior testimony patterns, challenge history, and documented bias indicators
- Jurisdiction benchmarks: verdict ranges and motion-grant rates for the specific judge and venue
OraClaim's automated benchmarking tags each claim across dozens of dimensions — plaintiff counsel, plaintiff expert, alleged injuries, treatment patterns, and jurisdiction — then runs continuous comparisons against the full historical case library. When a demand deviates from the pattern for that attorney and fact type, the deviation surfaces immediately, not weeks into the file.

The platform's portfolio management module also surfaces exposure by plaintiff counsel concentration — which naturally flags situations where the same attorney appears across a disproportionate number of active files, a key indicator of coordinated activity.
Limitations and Considerations for AI Fraud Detection in Claims
Data Quality and Bias Risks
AI models are only as accurate as the data they're trained on. Incomplete records, historically biased claim outcomes, or imbalanced training sets can produce false positives that unfairly flag legitimate claimants or miss fraud patterns from underrepresented data. The NAIC's 2023 AI Model Bulletin expects insurers to maintain governance frameworks, model validation, ongoing monitoring for model drift, and third-party due diligence for any AI system used in claims handling.
Human oversight isn't optional in this context. AI should surface anomalies for review, not make final determinations. OraClaim's design reflects this principle: all outputs are produced as work product for attorney or claims professional review, not as independent decisions.
Compliance and Data Privacy
Claims data is among the most sensitive information an organization handles. Protected health information, privileged legal communications, and personally identifiable information all coexist in a single claim file.
Any AI platform deployed in this context must comply with:
- HIPAA business associate requirements
- State insurance data security laws (including NY DFS, NAIC model act adopters)
- NAIC AI governance expectations for model oversight and validation
- Data encryption, authentication, and access control standards
OraClaim operates as a closed, access-restricted SaaS system to preserve attorney-client privilege and work-product protections. Third-party sub-processors are contractually prohibited from using customer data for model training or any independent purpose — a hard requirement when handling privileged legal data.
What to Look for in AI-Powered Claims Management Software
Purpose-Built for Claims, Not Financial Services
General-purpose fraud detection tools built for banking and payments are not the same as platforms built for claims management. Claims-specific platforms natively process legal demand packages, medical records, physician notes, and coverage correspondence without extensive customization.
Generic tools require significant configuration to handle claims document structures and often still miss domain-specific nuance.
OraClaim is built specifically for the defense workflow — not generic legal AI, and not first-notice-of-loss systems designed for policy administration rather than claims defense document analysis.
Integration With Existing Systems
Fraud signals are only useful if they surface within existing workflows. Platforms that force adjusters or defense attorneys to switch between disconnected systems reduce adoption and delay action. Look for:
- Established integrations with practice management systems (Clio, MyCase, Smokeball, PracticePanther)
- Document management integrations (NetDocuments, iManage, Box, Worldox)
- Clear integration implementation process
Explainability and SIU-Ready Output
AI fraud flags without documented justification are not actionable — and in some contexts create more risk than they resolve. Evaluate whether a platform produces:
- Specific anomaly documentation with supporting evidence
- Relationship maps showing cross-claim connections
- Benchmarking data that contextualizes why a claim is flagged
- Audit-ready output usable in SIU referrals and litigation
Frequently Asked Questions
How is AI used in claims management for fraud detection?
AI analyzes structured claim data (billing codes, dates, amounts) and unstructured documents (medical records, demand letters) using machine learning, NLP, and pattern recognition. It establishes baselines for normal claim behavior, flags deviations in real time, and generates risk scores that enable faster, more accurate fraud identification than manual review.
What types of fraud can AI detect in insurance claims?
AI detects exaggerated injuries, duplicate or inflated billing, staged incidents, provider-attorney fraud rings, and claimants with multiple simultaneous open claims. Its ability to analyze cross-claim data makes it especially effective against coordinated network fraud that's invisible when reviewing claims individually.
How does AI fraud detection differ from traditional rule-based systems?
Rule-based systems apply fixed thresholds and generate high false-positive rates, while missing fraud that operates just below trigger levels. AI uses adaptive machine learning to recognize complex, multi-variable patterns and continuously improves its accuracy without manual rule updates as fraud tactics evolve.
What data sources does AI analyze to identify fraudulent claims?
AI draws from historical claims records, medical billing data, legal demand letters, physician notes, claimant profiles, provider relationship data, and external reference databases. Cross-referencing structured and unstructured sources across these inputs is what gives AI its detection edge over single-source analysis.
Can AI fraud detection reduce false positives in the claims process?
Modern AI systems using ensemble models and explainable scoring balance sensitivity and precision, significantly reducing false positive volume compared to rule-based systems. Human review remains essential for borderline cases, with AI narrowing the field so professionals focus their judgment where it counts.
What should claims professionals look for in AI-powered claims management software?
Prioritize domain-specific design for claims (not generic fraud tools), integration with existing practice management systems, explainable output that supports SIU referrals, and enterprise-grade data security with closed architecture to preserve privilege. OraClaim is built specifically for defense lawyers and claims professionals, with native processing for legal and medical document types and an access-restricted system designed around those requirements.